
Bulk Dispense
Module Guide - A Deeper Dive!

Introduction
Central to the formulation and batching modules, V5 Traceability effortlessly integrates with bulk dispense systems, enhancing the efficiency of ingredient additions during production.
Crafted for high-volume, bulk-fed ingredients, whether dry or liquid, V5 Traceability ensures unparalleled tracking precision for both mixed and separated lots.
With V5 Traceability at the helm, ingredient movements from silos or other bulk containers straight to mixers are under constant surveillance, detailing lots used and batches produced. This acute oversight is crucial, providing a safeguard against potential high-stake recall situations.
Additionally, V5 Traceability is engineered for flawless synchronization with PLC Systems. Visualize a PLC guiding an ingredient from a silo to a hopper in preparation for mixing; V5 captures this move digitally, rendering manual records redundant. Such adaptability underlines V5 Traceability’s position at the forefront of modern automation solutions.
Table of Contents
1. Communication Methodologies
When we then come to produce this formula, there are 2 different ways that V5 Traceability can communicate with the bulk dispense system to fulfil the bulk dispense step.
1.1. File Exchange
The first method that V5 Traceability can use to interact with a bulk dispense system is via file exchange, utilizing the SG Data Engine. This works by V5 Traceability recognizing when a bulk dispense step is required and generating an XML file in the Data Engine’s ‘export’ folder (found at ‘installdir/SG Data Engine/export’). Exactly when this file is generated depends on the dispensing method (see below).
This XML file must then be transferred to the bulk dispense system for processing. This can be done via FTP, shared directories or any other file sharing method that you may wish to employ.
The bulk dispense system will then modify the file to state how much of the required commodity it dispensed, and then the XML file will be returned to the ‘import’ folder of the SG Data Engine (found at ‘installdir/SG Data Engine/import’), where it will be processed by the Data Engine, which in turn feeds this through to the V5 Terminal to fulfil the bulk dispense step.
1.2. Streaming
The second method that V5 Traceability uses for bulk dispense system interaction is via network streaming. This method makes use of the same XML file transfer, but this is now done automatically via a direct TCP/IP connection to the bulk dispense system to fulfill the required bulk dispense steps.
The bulk dispense system can then return the completed weight data back via the TCP/IP connection in the same format as defined in the XML file.
2. Formula Setup
Bulk Dispense steps can be added to a formula in Control Center the same way as any other step type.
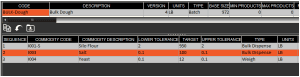
To do this is would simply be a case of adding a new formula step (1) in the lower panel of the ‘Formulas’ window of Control Center, and then setting this new step as ‘Bulk Dispense’ step (2). Steps that might have previously been ‘Key Entry’ before the integration of a bulk dispense system can be changed to ‘Bulk Dispense’ by simply changing their type.
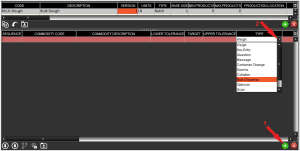
Ingredients with their weight targets and tolerances can be entered as normal to complete the setup of this formula step.

We could then complete the formula setup using more bulk dispense steps, or steps of any type. Let’s add 2 extra ‘weigh’ steps to complete this basic formula.

3. Dispense Methodologies
As mentioned above, the timing of the XML file generation, used for both the file exchange and streaming methods, is dependent on whether the system is set for multiple dispense or not. Let’s see the differences by using an example of each below while using the file exchange method.
3.1. Linear/In Sequence
The first way we can process a bulk step is on a per-step basis. Essentially this will cause the system to export a bulk dispense request once the Terminal reaches a ‘Bulk Dispense’ step. Let’s see how this works by running the formula we created above in this mode.
Once we start this formula, since the bulk dispense step is the first step, we will immediately see the following screen informing us that this is a bulk step:
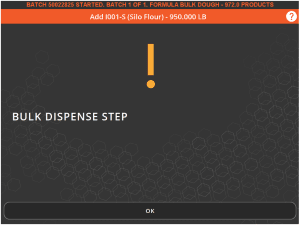
Hitting OK here will then prompt for a scale selection. We need a bulk dispenser to be set up in the system prior to this, which SG Systems can assist with prior to implementation of this feature. We would need to select this scale to proceed.
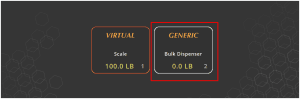
Once we select this ‘Bulk Dispenser’, we will be taken to the next screen, where the Terminal is awaiting input from the dispenser.

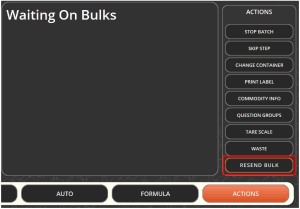
At the same time as selecting the bulk dispenser, if using the file exchange communication methodology, the aforementioned XML file will be exported to Data Engine’s export folder.

The system has the ability to resend this file if required.
If we open this file up, we can see that the bulk dispenser will be asked to complete the ‘achievedQty’ field in this file.

This file will then be picked up and transferred to the bulk dispenser via either file exchange or TCP/IP streaming, where the weight data will be inputted by the bulk dispense system once the dispensing is complete and a final stable weight is gathered.
When returned, the file will then look something like this (note that we are within tolerance for this step as per the step setup):
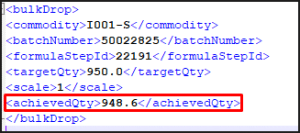
This file will then be returned to Data Engine’s ‘import’ folder, and once this is done, it will be picked up by Terminal and the bulk dispense step will be fulfilled and Terminal will move to the next step, in this case adding the salt and yeast. This example XML file can be downloaded here.
3.1.1. Location Assignments
To further streamline the above process, location assignment can be used to automate more of the process, allowing us to:
- Set a location that the Terminal will automatically draw bulk lots from (i.e. a silo)
- Assign a location to an individual bulk dispenser, meaning that the location of a particular lot that we might select will determine which bulk dispenser is used for the bulk dispense step.
3.2. Using Multiple Dispense
As we saw above, if we use the linear dispense methodology, then the required XML file will be generated at the point of the V5 Terminal reaching an individual bulk dispense step. However, this method may be unsuitable for some facilities due to bulks being weighed separately to the rest of the production process, and often not at the same time. To allow more flexibility in this regard we can use multiple dispense. To better illustrate how this would work, let’s add another bulk dispense step to the formula we have been using so far.
How this differs from what was discussed earlier is that multiple XML files can be generated at once (if required) and these files will be generated as soon as the job is scheduled, rather than when the Terminal reaches that step. Let’s see how this works by scheduling 5 batches of our modified formula:

As soon as we do this, we can see that 5 XML files have been generated immediately, one for each batch:
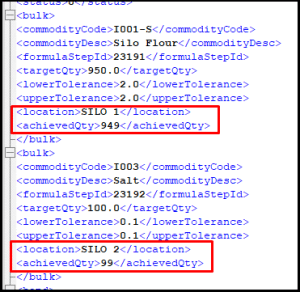
If we open up one of these files we can see that these look slightly different to the files generated earlier in the per-step method. We can see how, by listing each step, we can fulfil multiple bulk steps for one batch, allowing us to fulfil both the flour and salt bulk drops in one file.

This method also allows for more detailed entry of stock deduction by referencing a location where the stock is drawn from, for example a silo.
As with the linear method, these files can be transferred to and from the bulk dispense system via either file exchange or TCP/IP connection.
When the files are returned from the dispenser, they will have both the ‘achievedQty’ and ‘location’ filled appropriately for each bulk step(s):
This example XML file can be downloaded here.
Let’s imagine that our bulk dispensing for batch 1 is done in the morning, and then in the afternoon the ingredients are added to the mixer. In this case, the completed XML file for batch 1 will be dropped into the Data Engine’s import folder and processed. The data engine will then queue this bulk dispense step and await the relevant job and batch, as denoted in the file name.
So if we go to our Terminal now and start this job we will be asked to hand weigh our yeast:

After which, the system will process the bulk dispense information from the XML file and automatically complete the batch.
If all the bulk components for all batches have been dispensed and the associated XML files returned to the Data Engine, then the remaining batches will proceed in the same way until the job is complete.
The key point to take away from this process is that the weighing of multiple bulk components of a formula can be processed at any time compared to the remaining hand added steps. In our example here, we weighed the bulks earlier in the day, but these could have been done days in advance of the job being executed, they could be processed along with the job, or even added later, depending on the system setup.
We can also configure the system to completely separate the bulk process from the hand additions, with them being processed at different Terminals if required.